Intro
When we hear the word tree before we know the tree of computer science, the image of the tree of real-life floats in our eyes. The concept of the tree in Computer Science is similar to a real-life tree. But it’s the inverse version of a real-life tree. That is, the root of the tree remains above instead of below. There is nothing to worry about if it seems random right now. We will learn more details gradually.
By the way, a tree is a hierarchical data structure. It’s one of the most popular data structures and is used widely in various fields. Our computer file structure is an appropriate example of it.
Assume that there is a folder called Books on our computer. Inside that folder, there are two more folders called Fiction and Non-fiction. And we put our books in these two folders by category. The way we arranged the whole thing, we can call this arrangement a tree-type structure.
We can represent this whole file structure scenario using a tree. Let’s see a visual representation of it. Remember, in computer science, a tree always grows down.
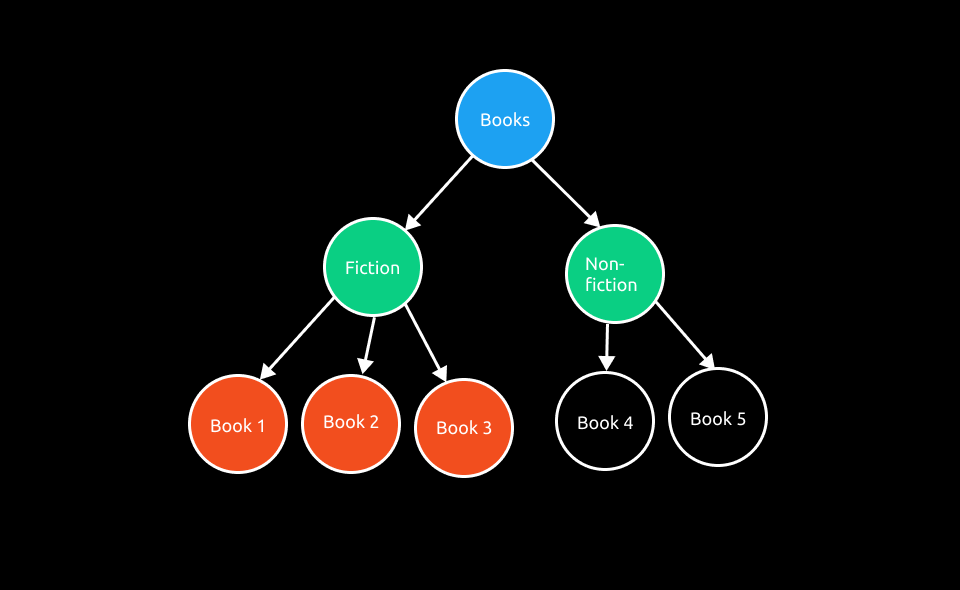
A tree is a collection of nodes, where each node contains data and references. In our visual example, each Circle is a node. For example, the Circle with the title Books (the title ‘Books’ is data of this node) is a node that points to two more nodes. Remember, not every node points to another node. We will discuss it later.
Let’s know about some essential keywords of a Tree data structure.
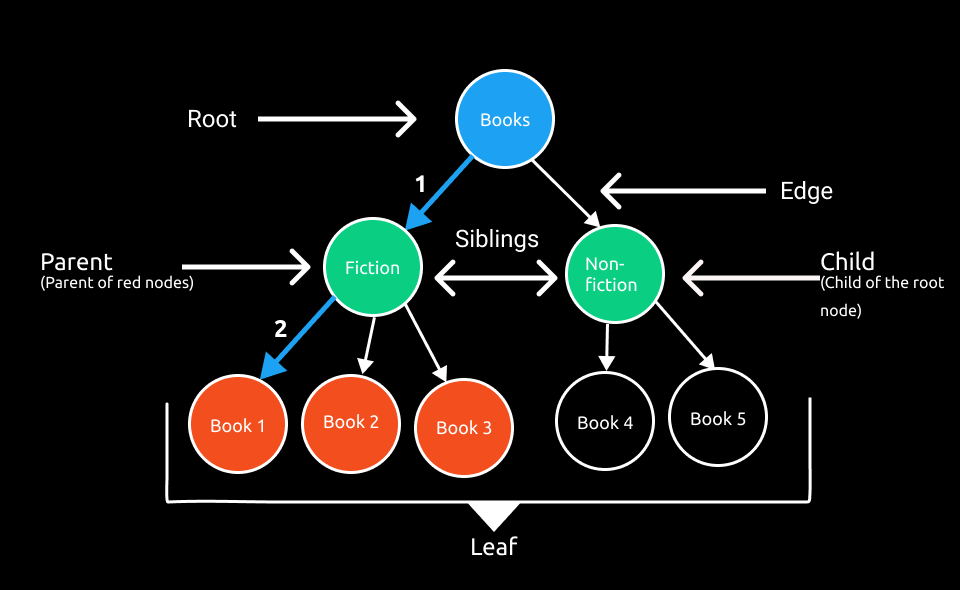
Root
Generally, if there is a tree, there must be a root node of that tree. The root is the topmost node in a tree hierarchy. There can only be one root node in a tree. The other nodes in a tree hierarchy can’t point to the root node, or they don’t have a reference to the root node. A tree starts from the root node. In our example, Books is the root node. In a word, the root is a node with no parent.
Edge
The connection between two nodes is known as Edge. In the above example, there is a visual example of an edge.
Parent and Child
A parent is a type of node that stores references of other nodes or points to other nodes. In our example, the root node is the parent of the Fiction and Non-fiction node. Similarly, the Fiction node is the parent of Book 1, Book 2, and Book 3 (Nodes with the red backgrounds).
So, it’s pretty easy to assume that what child node is. Yes, you got the idea. Remember, a child node can have only one parent. In our example, Red nodes are children of the Fiction node. Similarly, green nodes are children of the root node and so on.
Leaf
It’s pretty simple. A node with no children is called a leaf node. In our visual example, the nodes with red and transparent backgrounds are leaf nodes.
Siblings
Nodes with the same parent are called siblings. See the visual example above. Green nodes are the child of the root node, so they are siblings. Similarly, you can find out other siblings’ nodes from the visual.
Depth
The depth of a node is the number of edges from the root to the node itself. For example, the depth of node Fiction is 1. From root node to Fiction node, there is only one edge. Similarly, we can find the depth of the Book 1 node. See the visual example.
Height
The measuring height of a tree is almost similar to depth. But this time, we have to find out the longest path from the root to a leaf. And then count the number of edges. But it might become a bit confusing for a beginner to find out the longest path from the example. Because there, we will get more than one longest path with the same number of edges. But it’s okay. We can pick one from them.
If we add a new node as a child of Book 1 node and give it a name called Another Book, then our longest path will be Books -> Fiction -> Book 1 -> Another Book. And the height of the tree will be 3.
Last Words
There are so many things to learn about Tree data structure. This blog will help you to start.
I hope you got a basic understanding of Tree data structure.